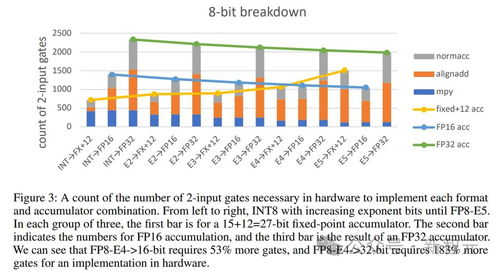
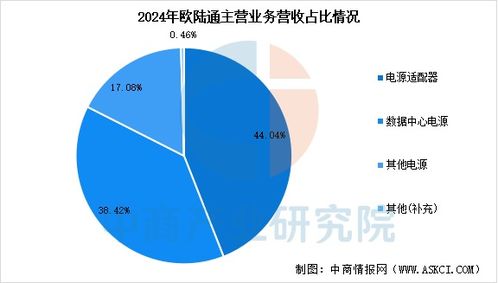
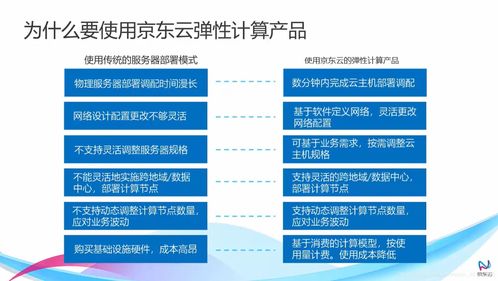
大數據架構的演進 數據處理與存儲支持服務的迭代路徑
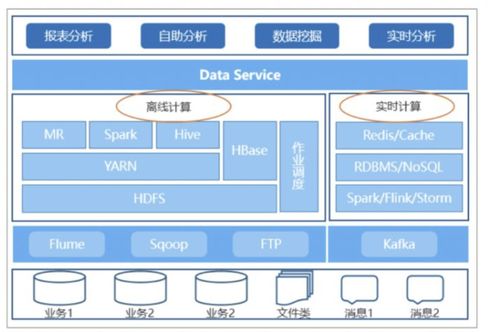
隨著數據量的爆發式增長和應用場景的不斷擴展,大數據架構經歷了從傳統批處理到實時流處理、從單一存儲到多模態服務的重要迭代。這一演進不僅提升了數據處理效率,也推動了存儲支持服務的多樣化和智能化發展。
在早期階段,大數據架構主要依賴Hadoop生態系統,以批處理為核心。MapReduce作為典型的數據處理引擎,適用于離線數據分析任務;而HDFS(Hadoop分布式文件系統)提供了可靠的存儲基礎。批處理模式延遲較高,難以滿足實時業務需求。
隨著技術的發展,架構開始向Lambda和Kappa等混合模式迭代。Lambda架構結合了批處理和流處理層,通過批層處理歷史數據、流層處理實時數據,再通過服務層合并結果。這引入了如Apache Spark(用于批處理)和Apache Flink(用于流處理)等引擎,顯著提升了處理靈活性。同時,存儲支持服務也從單一的HDFS擴展至NoSQL數據庫(如HBase、Cassandra)和對象存儲(如AWS S3),以支持多樣化的數據模型和訪問模式。
近年來,云原生和實時化成為迭代的關鍵方向。架構演進為以Kubernetes為基礎的容器化部署,數據處理服務如Apache Kafka和Apache Pulsar提供了高吞吐的消息隊列,支持事件驅動數據流。存儲服務則進一步融合了數據湖和數據倉庫概念,例如Delta Lake和Snowflake,實現了ACID事務和統一查詢,提高了數據一致性和可管理性。AI驅動的自動化運維和Serverless計算模型,正在降低大數據架構的復雜性,讓數據處理和存儲服務更彈性、更智能。
總體而言,大數據架構的迭代體現了從集中式到分布式、從離線到實時、從單一存儲到多服務集成的轉變。未來,隨著邊緣計算和物聯網的普及,架構將進一步向去中心化和智能化演進,數據處理和存儲支持服務將更注重低延遲、高可用和可持續性,賦能企業在數據洪流中持續創新。
如若轉載,請注明出處:http://m.hrbxjj.cn/product/25.html
更新時間:2026-01-08 08:43:40